
Mental Health Insights from Social Media: Classifying Stress with Transformers
While stress can serve as a motivator in certain situations, long-term high levels of stress can adversely affect health in several ways. The American Medical Association (AMA) has found that chronic stress is associated with an increased risk of hypertension and heart disease (“Chronic Stress and the Heart | Cardiology | JAMA | JAMA Network” n.d.). Prolonged stress may also impair immune function, potentially increasing susceptibility to infections. Additionally, chronic stress is associated with psychiatric disorders, including depression and anxiety (Turner and Lloyd 2004).
The widespread use of social media is providing new opportunities for researchers to assess stress at both individual and population levels. People often share their daily experiences, thoughts, and emotions on platforms such as Twitter, Facebook, Reddit, TikTok, and Instagram. This user-generated content produces real-time, time-stamped data that can reflect individual and collective well-being, including stress levels.
Advances in Natural Language Processing (NLP) have significantly improved the ability to infer psychological states from textual data. Transformers represent the current state of the art in classifying and interpreting natural language. Recent improvements in context handling, including attention mechanisms and transformer architectures, have greatly enhanced their performance in understanding complex language patterns.
This article investigates the performance of models on social media posts by examining different Transformer architectures. It evaluates the effectiveness of fine-tuning and prompt-based methods, aiming to identify best practices and trade-offs through performance comparisons across various models.
Reddit Dataset for Stress Analysis
The Dreaddit: A Reddit Dataset for Stress Analysis in Social Media presents a dataset consisting of a selection of posts from various categories of Reddit communities for the purpose of stress analysis (Turcan and McKeown 2019). Reddit is a social media platform where users post in topic-specific communities called subreddits. The relatively lengthy nature of these posts makes Reddit an ideal source of data for studying the nuances of psychological states such as stress.
To analyze stress, ten subreddits were selected where members are likely to discuss stressful topics. The dataset contains approximately 190K posts, of which 3K were manually labeled for stress using Amazon Mechanical Turk. The table below shows example messages and their corresponding labels, where ‘1’ indicates stress and ‘0’ represents no stress or a neutral tone.
| Message | Label |
|---|---|
| Hello wonderful world of Reddit! My boyfriend and I rescue animals in need. We’ll foster them for however long it takes to find them a home |
0 |
| I have a fear of fainting so I was like “what if I fainted from so much fear during this test” and next thing you know, worst panic attack of my life during the quiz and I failed it |
1 |
| For hours on end I contemplate and procrastinate everyday about my depressing life. It’s just sad. |
1 |
The study also evaluated both traditional and neural supervised learning methods for identifying stress in the dataset. Models were trained using the labeled portion of the data, and classification metrics were computed using a held-out test set. The metrics are defined as follows:
- Precision: When the model predicts class 1 (stress), how often is it correct?
- Recall: How well does the model identify all instances of class 1?
- F1-score: The harmonic mean of precision and recall, providing a balanced measure of a model’s accuracy.
Summary of model performance:
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Convolutional Neural Network + features | 0.6023 | 0.8455 | 0.7035 |
| Convolutional Neural Network | 0.5840 | 0.9322 | 0.7182 |
| GRNN w/ attention + features | 0.6792 | 0.7859 | 0.7286 |
| GRNN w/ attention | 0.7020 | 0.7724 | 0.7355 |
| Bag of N-Grams | 0.7249 | 0.7642 | 0.7441 |
| Bag of N-Grams + features | 0.7474 | 0.7940 | 0.7700 |
| Logistic Regression w/ pretrained Word2Vec + features | 0.7346 | 0.8103 | 0.7706 |
| Logistic Regression w/ fine-tuned BERT LM + features | 0.7704 | 0.8184 | 0.7937 |
| Logistic Regression w/ domain Word2Vec + features | 0.7433 | 0.8320 | 0.7980 |
| BERT-base | 0.7518 | 0.8699 | 0.8065 |
Several models incorporated manually engineered psycholinguistic and lexical features, including:
- Linguistic Inquiry and Word Count (LIWC): Measures language associated with emotion, social concerns, and cognitive processes.
- Sentiment scores
- Readability scores
- Word frequency statistics
- Post metadata (e.g., post length)
The best-performing model was BERT-base without engineered features. At the time of the study (2018), BERT models represented the state-of-the-art in large language models for text classification. In the following sections, we will explore how further advances in Transformer architectures and training approaches can enhance stress analysis in social media.
Fine-Tuning Encoder Transformers
Encoder-only transformers, such as BERT, RoBERTa, and ALBERT, are suited for classification tasks because they use bidirectional self-attention — each token attends to both its preceding and succeeding tokens in the input sequence. These models are relatively small (typically ranging from 100 million to 300 million parameters), making them efficient in terms of inference resources and suitable for real-time applications.
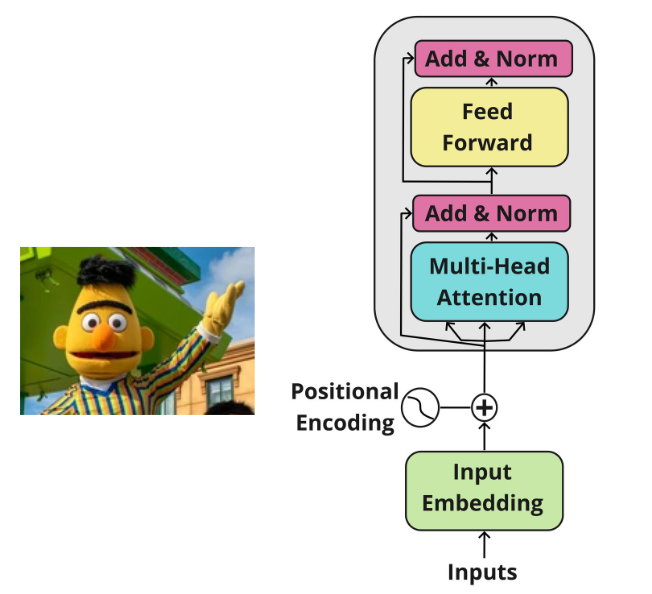
Encoder Transformer
These models are typically pretrained on large general-purpose corpora. You can then fine-tune them on a dataset specific to your classification task (e.g., sentiment analysis, spam detection). Since the models are compact compared to large language models (LLMs), the actual model weights can be updated during fine-tuning, and the compute requirements are relatively modest.
You can fine-tune and use a BERT model for inference with straightforward steps. For an example Jupyter notebook see Fine Tune Mentalbert and Robert Classification
- Pre-process the Dreaddit training, validation and test data.
- Load a BERT model specifying number of labels (2). This creates a linear layer on top of BERT’s output for classifications.
- Run fine-tuning using the training and validation datasets. This adjusts BERT’s pre-trained weights and the classification layer.
- Run inferences on test data set.
- Calculate probability for for class ‘1’ using logit and determine the best threshold.
- Run Classification report for precision, recall and F1 metrics.
When fine-tuning an encoder-based transformer model for classification tasks, you can obtain an estimate of the probability associated with each class. These are derived from the model’s output logits. LLM logits are the scores a language model assigns to each possible next token before converting them into probabilities. This can provide a reasonable estimate of the class probability. These probability estimates are helpful for setting a decision threshold—a cut-off value that determines whether the model predicts a particular class. For example, setting a threshold of 0.6 for class ‘1’ means the model will classify an input as class ‘1’ only if the predicted probability for class ‘1’ is greater than or equal to 0.6.
Since the 2018 Dreaddit study, there have been a number of improvements and BERT variants. Larger model are available with more training (RoBERTa). Smaller, faster models with performance similar to BERT-base were developed (ALBERT). Also, BERT models are available with domain specific training. Models are available in the following categories:
- Biomedical and Healthcare BERT Models
- Financial BERT Models
- Legal BERT Models
- Cybersecurity BERT Models
- Conversational and Social Media BERT Models
- Code and Software Engineering BERT Models
- Multilingual and Low-Resource Language BERT Models
The healthcare models include MentalBERT which was pre-trained on mental health–related text to detect signs of depression, anxiety, suicidal ideation, or other psychological conditions (Ji et al. 2021). It was trained using Reddit subreddits related to mental health, but only one subreddit was used from the Dreaddit study (anxiety). Using the fine-tuning and inference steps above, the following table show performance compared the BERT-base in the Dreaddit study.
| Model | Precision | Recall | F1 Score | Parameters | Train Time | Inference Time |
|---|---|---|---|---|---|---|
| BERT-base (fine tune) | 0.75 | 0.87 | 0.81 | 110M | ? | ? |
| MentalBERT (fine tune) | 0.90 | 0.79 | 0.84 | 110M | 5 min | sub second |
MentalBERT has a better overall F1 score (0.84 vs. 0.81), driven largely by higher precision. However, it has a lower recall, indicating it is missing more messages labeled as ‘stress’ compared to BERT-base. Depending on the objectives of the stress identification project — such as whether minimizing false negatives or false positives is more critical — MentalBERT may be a better choice.
Note that the BERT models are fast. For this example the training takes only a few minutes and inferences are sub-second on free GPU platforms like Google Colab and Kaggle.
Fine-Tuning Decoder Transformers
Decoder transformers (decoders) generate text one token at a time, where each generated token attends only to the preceding tokens. Unlike encoders, decoders are not designed to create a representation of the input text; rather, they predict the next token in a sequence. Typically, decoders produce multiple tokens in response to input text, but techniques exist to constrain them to output a single token for classification tasks.
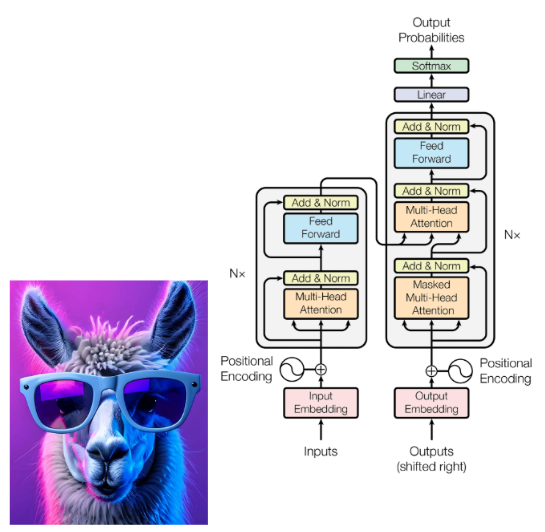
Decoder Transformer
Since 2018, decoder-only transformers have grown significantly in both size and training scale. Early models had fewer than 200 million parameters and were trained on relatively small, curated datasets. Within just a few years, they scaled to hundreds of billions of parameters, trained on massive corpora containing hundreds of billions to trillions of tokens. This increase in scale has enhanced their capacity to model complex language patterns and subtle linguistic distinctions.
To configure, train, and deploy large pre-trained models, you can use model wrapping services like Hugging Face Transformers. These services manage the complexities involved in working with large language models (LLMs), making them accessible to researchers and developers without deep expertise in machine learning. The services relevant to this study are described below.
Loading a Model with a Specific Task
Model wrapping services allow you to download pre-trained models and configure them for specific tasks. In our case, we want the decoder to perform classification rather than generate the next tokens. To support this, the service adds a classification head—typically a linear layer—to the output of the model. During fine-tuning, this head is updated based on the correct labels.
Model Quantization
Very large models can be accessed using an application programming interface (API), while medium-sized models (e.g., with around 7 billion parameters) can sometimes be deployed locally, depending on hardware. If resources are limited, a smaller or quantized version of the model can be used. Quantization reduces the precision of the model’s weights—typically stored as 32-bit floating point numbers—to lower precision formats such as 16-bit, 8-bit, or even 4-bit. This reduces memory usage and computational load, but it can reduce model accuracy.
Model Fine-Tuning
Fine-tuning all parameters of large decoder models is often impractical due to resource constraints. Low-Rank Adaptation (LoRA) is a commonly used fine-tuning method that adds a small number of trainable weights to layers of the model. This reduces the resource usage and enables training on consumer-grade hardware.
You can follow these high-level steps to fine-tune a decoder model locally. For an example, see the Jupyter notebook Fine Tune Phi 3 and Llama Classification
- Pre-process the Dreaddit training, validation and test data.
- Use a model wrapping service to load and adapt the model
- Run fine-tuning using the training and validation datasets.
- Run inferences on test data set.
- Calculate probability for class ‘1’ using logit and determine the best threshold.
- Run Classification report.
- Specify model quantization depending on platform resources.
- Define the number of labels to use in a classification head.
- Define the LoRA configuration for fine-tuning.
The following table show a comparison of using DeepSeek and Phi-3 for classification.
| Model | Precision | Recall | F1 Score | Parameters | Train Time | Inference Time |
|---|---|---|---|---|---|---|
| BERT-base (fine tune) | 0.75 | 0.87 | 0.81 | 110M | ? | ? |
| MentalBERT (fine tune) | 0.90 | 0.79 | 0.84 | 110M | 5 min | sub second |
| DeepSeek (fine tune) | 0.71 | 0.94 | 0.81 | 7B | 4 hours | 4 min |
| Phi-3 (fine tune) | 0.83 | 0.83 | 0.82 | 1.3B | 6 hours | 4 min |
Note that although we are using decoders that were not designed to find a representation of text input, we get good F1 Scores. But there is much larger resource usage and the training & inference times are long.
Classification Using Prompts
If you do not have labeled data, transformer decoders can be an effective solution for text classification. As discussed earlier, decoders generate multiple tokens in response to input text. However, prompts can be engineered to direct the decoder to perform classification tasks. In this study, prompts were used to define the attributes of the classes “stress” and “no stress,” and to ask for classification of social media messages.
The engineering of the prompt is critical and will often require experimentation for the best results. For a classification task the following are important:
- Use concise, consistent terminology. State that the task is a “classification” task and refer to the outcomes as “classes.”
- Separate instructions from input text. Also, it helps to explicitly state how many messages are being classified.
- Limit the number of messages per prompt. Fewer messages tend to improve classification accuracy.
- Ensure output is parseable. Provide formatting instructions so that classifications can be extracted. Indicate how many outputs to expect.
- Set temperature=0. This encourages deterministic outputs from the model.
For this study, multiple prompts were tested using different definitions of stress. The most effective prompt was based on the definition provided to human labelers in the Dreaddit study. This makes sense, as the results are being compared to Dreaddit labels. The prompt used is shown below:
Messages can be classified as follows:
'1' is the class that indicates a state of mental or emotional strain or tension resulting from adverse or demanding circumstances.
'0' is the class that indicates the speaker is not expressing a state of mental or emotional strain or tension resulting from adverse or demanding circumstances.
Output a single line of comma separated classes the 2 messages beginning with the word "Classifications": There should be 2 classes in the line.
Output a single line of comma separated probabilities for class '1' beginning with the word "Probabilities": There should be 2 probabilities in the line.
Use a temperature=0 for deterministic output.
message: 'Its like that, if you want or not.“ ME: I have no problem, if it takes longer. But you asked my friend for help and let him wait for one hour and then you haven’t prepared anything. A good resource for prompt design is Prompt Engineering Guide. But note that even with a great prompt, some models will not give consistent output. This is particularly true with small to medium size models.
Some decoder models are better suited for classification. These models are optimized for instruction-following tasks and are trained or evaluated using classification benchmarks. Microsoft’s Phi-3, for example, is a decoder specifically optimized for such tasks. Models trained in the relevant domain (e.g., mental health) may also perform better on related classification tasks.
The high level steps for using a decoder in a local environment for prompt classifications follow. For an example Jupyter notebook see Classification Using Different Prompts
- Pre-process the Dreaddit training, validation, and test data. For Dreaddit, tokenization of inputs is sufficient.
- Construct prompts with input messages, then tokenize. Multiple batches may be needed depending on context length.
- Generate output using deterministic settings (temperature=0).
- Parse the output to extract classes and probability of class ‘1’.
- Determine the best probability threshold and generate a classification report.
The following table shows the metrics using the Phi-3 model with a prompt based on the Dreaddit Study stress definition.
| Model | Precision | Recall | F1 Score | Parameters | Train Time | Inference Time |
|---|---|---|---|---|---|---|
| BERT-base (fine tune) | 0.75 | 0.87 | 0.81 | 110M | ? | ? |
| MentalBERT (fine tune) | 0.90 | 0.79 | 0.84 | 110M | 5 min | sub second |
| DeepSeek (fine tune) | 0.71 | 0.94 | 0.81 | 7B | 4 hours | 4 min |
| Phi-3 (fine tune) | 0.83 | 0.83 | 0.82 | 1.3B | 6 hours | 4 min |
| Phi-3 (Dreaddit prompt) | 0.64 | 0.81 | 0.72 | 1.3B | na | 1 sec |
| Phi-3 (10 shot prompt) | 0.58 | 0.95 | 0.72 | 1.3B | na | 1 sec |
The results of using a prompt with a few labeled messages as examples is also shown. Prompts providing examples are called few-shot prompts – in our case we are using 10 examples. Few shot did as well as the Dreaddit prompt which makes sense. So why aren’t these performing well? This is likely because the decoder is relying on its pretraining—particularly its understanding of the term stress—rather than being explicitly trained on the task’s labels. You may find that using a larger model with more training yields better results. This is probably the case as a test with Claude-3.7 shows an improvement in the F1 Score.
| Model | Precision | Recall | F1 Score | Parameters | Train Time | Inference Time |
|---|---|---|---|---|---|---|
| BERT-base (fine tune) | 0.75 | 0.87 | 0.81 | 110M | ? | ? |
| MentalBERT (fine tune) | 0.90 | 0.79 | 0.84 | 110M | 5 min | sub second |
| DeepSeek (fine tune) | 0.71 | 0.94 | 0.81 | 7B | 4 hours | 4 min |
| Phi-3 (fine tune) | 0.83 | 0.83 | 0.82 | 1.3B | 6 hours | 4 min |
| Phi-3 (Dreaddit prompt) | 0.64 | 0.81 | 0.72 | 1.3B | na | 1 sec |
| Phi-3 (10 shot prompt) | 0.58 | 0.95 | 0.72 | 1.3B | na | 1 sec |
| Claude (Dreaddit prompt) | 0.83 | 0.78 | 0.81 | 175B | na | 1 sec |
Note that in the prompt classification example shown above, our prompt asks for the probability of a class and we use probabilities to determine the best threshold for classification. Asking for a probability can cause the model to use a quantitative approach. Decoder transformers can classify text using both qualitative and quantitative methods. A qualitative approach relies on contextual understanding, semantic meaning, and patterns in the text. In contrast, quantitative-style prompts encourage the model to produce structured outputs, such as confidence scores or class probabilities. With this approach, the model may count keywords that are similar to the class and use a keyword percentage as a probability estimate.
The approach giving the best classification performance depends on the task and the model used. For our example using Phi-3, a quantitative approach gives a better F1 score than using a prompt that encourages a qualitative approach. For Claude, a qualitative-style prompt gives better results.
Conclusion
Transformers demonstrate significant capabilities in inferring psychological states from text. If you have labeled data, fine-tuning BERT models is an effective approach—especially when leveraging models pre-trained in the relevant domain. In the absence of labeled data, decoder-based transformers paired with well-engineered prompts can be a viable solution. Larger decoder models tend to perform better, and domain-specific pretraining can further enhance results.
You’re encouraged to explore the provided Jupyter notebooks to experiment with different models, prompts, and fine-tuning parameters to find what works best for your classification project.
References
No responses yet