
“Exploring Social Determinants of Health through AI Topic Models”
There is growing recognition of the impact that social determinants of health (SDoH) have on individuals’ well-being, prompting increased efforts to document and address these factors. Traditionally, social determinants data have come from structured sources like surveys, interviews, and registrations. Recently, natural language processing (NLP) is being employed to identify these factors from unstructured text sources, such as notes, messages, and chats, through topic analysis. Large language and clustering models identify topics by analyzing patterns in word usage, context, and relationships within large datasets, enabling them to recognize themes and relevant concepts within text. These “topic models” are proving to be effective in enhancing documentation on social factors. This article provides an overview of topic modeling and demonstrates how these models can be applied in unsupervised modes. An example analysis using BERTopic will illustrate how social factors can be extracted from publicly available sources.
The Value of Topic Modeling for SDoH
The lack of comprehensive social determinants of health (SDoH) data is a significant hurdle for organizations in social services, healthcare, and urban planning. These sectors often require precise data to effectively address issues like poverty, education, employment, housing, and other factors impacting health outcomes. However, SDoH data is typically sparse, inconsistent, or siloed within different agencies, limiting its utility in creating impactful interventions.
In healthcare, there have been increasing calls for clinicians to document and attend to these factors (Medicine 2012). The Institute of Medicine of the U.S. National Academy of Sciences recommended that 10 SDoH domains be documented in electronic health records. However, studies find that these codes are rarely used (Guo et al. 2020). Researchers are now applying topic modeling to clinical notes to identify SDoH factors that may not be captured in structured health record fields.
City and community planning organizations are increasingly leveraging NLP to identify SDoH factors from unstructured data sources. City planning agencies often collect data from community surveys, public comments, and social media feedback to assess the needs and concerns of residents. Text mining techniques are applied to this data to identify mentions of SDOH, such as housing affordability, transportation access, or crime rates. For example, researchers in Los Angeles used topic modeling on public health data, environmental reports, and community surveys to identify key urban planning themes, such as air quality concerns, heat vulnerability, and access to green spaces. By identifying neighborhoods that frequently discussed these issues, planners could better address environmental inequalities and allocate resources to mitigate health impacts (Burke 1993)
Social support organizations also use NLP to mine public health data from community reports, research papers to assess SDOH at a population level. This helps in targeting specific areas with heightened social risk factors. They are also using social worker notes to identify factors for individuals. Studies have shown the effectiveness of topic modeling to extract SDoH themes in social work notes, demonstrating its potential for informing targeted interventions (Sun et al. 2024).
A Brief History of NLP Topic Analysis
Early NLP work was influence by linguistics and involved parsing and understanding natural language syntax, with little focus on topics or semantic meaning. In the 1970s and 1980s knowledge-based systems were developed that could categorize and understand topics using semantic networks and rule-based logic.
In the 1990s more data and computing power led to the rise of statistical methods in NLP. Latent Dirichlet Allocation (LDA) and other probabilistic models emerged, allowing researchers to classify documents by themes or topics without predefined categories. This decade marked the beginning of topic modeling as we know it.
In the 2000s NLP tasks became more sophisticated with the use of machine learning models, including Naive Bayes, Support Vector Machines (SVMs), and clustering techniques. Popular applications included spam detection and sentiment analysis.
In the 2010s word embeddings and neural networks revolutionized NLP by capturing semantic relationships between words and concepts. Recurrent Neural Networks (RNNs) and, eventually, Transformers (like BERT and GPT) led to high-quality topic understanding through contextual embeddings, dramatically improving topic detection accuracy and scalability.
Recently, large pre-trained language models like BERT and GPT-3 advanced topic analysis by leveraging massive corpora to understand nuanced relationships and context. Transformers and fine-tuning for specific applications now allow for real-time topic extraction, context-aware insights, and more accurate analysis in multiple languages.
How This Works with BERTopic
BERTopic is widely adopted for topic modeling and demonstrates the effectiveness of embedding and clustering technologies. Here are the main steps in topic analysis:
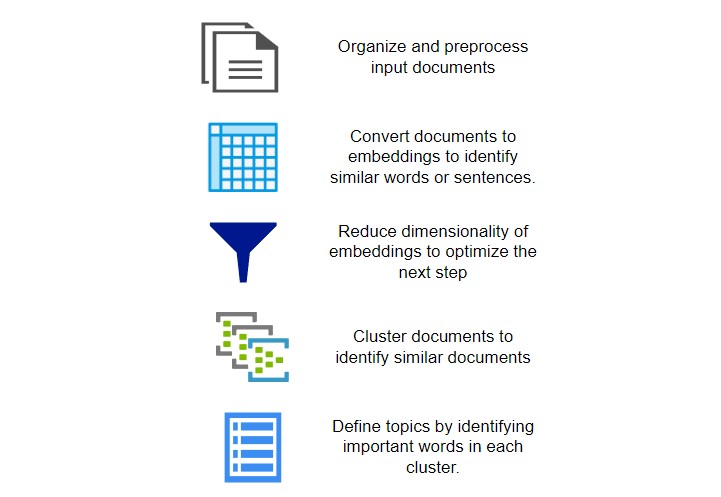 Topic Modeling Steps
Topic Modeling Steps
Before topic modeling, documents are organized and sometimes preprocessing is performed on documents depending on the application. For example, stops words might be removed from documents.
Embedding is a key step, where each word in a document is converted into a sequence of numbers, or a vector. Each value in this vector represents a weight for a specific dimension. For instance, in a two-dimensional embedding, the word “girl” might be represented by the vector [2, 6]. The aim of embeddings is to assign similar vectors to words that convey similar meanings.
The figure below is a simplified two-dimensional space, where the words “there,” “girl,” “woman,” “boy,” and “man” have dimensions that represent gender and maturity. Note that “girl” and “woman” have similar weights for gender. Also, “woman” and “man” have similar weights for maturity. The word “there” has no weights for gender and maturity. But in an actual embedding there would be more dimensions.
 Embedding Example in 2D
Embedding Example in 2D
Embeddings are usually trained on large text corpora, with each word’s vector determined by its proximity to other words within a set window (e.g., five words). During the training of a language model, an embedding layer can be included, functioning like a dictionary that retrieves the vector for each word. The vector’s weights are improved through backpropagation during training. If training data is limited or unavailable, pre-computed embeddings can be used. Pre-trained embeddings leverage general language features that are applicable across various tasks. A transformer-based model like BERT is often used but any other embedding model can be used.
The dimension weights in embedding vectors are used to determine the distance between words so that similar words can be grouped together. But embeddings can have hundreds of dimensions and as dimensionality increases, it becomes harder to measure distances between points. To address this, BERTopic uses dimensionality reduction algorithms to reduce the embedding dimensionality but preserves the local and global structure of the data.
Once the dimensions are reduced, BERTopic uses clustering algorithms to group similar documents together. This identifies clusters of points (documents) in the lower-dimensional space based on density—documents that are close together in this space are clustered into the same topic.
Finally, BERTopic assigns topic labels to each cluster. This identifies the most representative words from each cluster to form a human-readable topic. This is done by analyzing the words in the documents within each cluster and selecting terms that best describe the overall content of the cluster.
Example SDoh Topic Modeling
In this example, we’ll analyze text excerpts from reports, policy documents, and journal abstracts to identify topics related to social and environmental factors. Using BERTopic in an unsupervised mode allows us to explore all potential topics. If you’d like to try this example, you can use the Jupyter notebook: BERTopic SDG SDoH Topics.
Our input data will be sourced from the publicly available OSDG Community Dataset (Pukelis et al. 2022), which contains labeled text excerpts associated with the United Nations Sustainable Development Goals (SDGs) (“THE 17 GOALS | Sustainable Development” n.d.).
The SDGs are linked to social determinants of health (SDoH), offering a framework to enhance quality of life, reduce inequities, and create supportive environments. Key health-related SDGs include:
Addressing Poverty and Hunger (SDG 1 & 2)
Promoting Health and Well-Being (SDG 3)
Quality Education (SDG 4)
Gender Equality (SDG 5)
Clean Water, Sanitation, and Affordable Energy (SDG 6 & 7)
Reducing Inequality (SDG 10)
Creating Sustainable Communities (SDG 11)
Climate Action (SDG 13)
Each of the text excerpts in the OSDG Community Dataset have been labeled by volunteers with one of the SDG goals. We will focus our topic exploration on Creating Sustainable Communities (SDG 11). SGD 11 is important to SDoH as access to safe housing, public spaces, and sustainable cities impacts health by reducing exposure to pollution, crime, and other urban hazards. SDG 11’s focus on inclusive and sustainable cities supports health equity by promoting better living conditions.
Here’s the steps using BERTopic:
- Download the dataset from Zenodo.org. The dataset is updated regularly so you could check for more recent versions. The dataset has the following columns:
- doi – Digital Object Identifier of the original document
- text_id – unique text identifier
- text – text excerpt from the document
- sdg – the SDG the text is validated against
- labels_negative – the number of volunteers who rejected the suggested SDG label
- labels_positive – the number of volunteers who accepted the suggested SDG label
- agreement – agreement score
- For article excerpts on sustainable communities we will filter using sdg = 11
- The excerpts are sent to a sentence transformer to create sentence embeddings. Sentence embeddings are created using the embedding vectors from the words in the sentence.
- The documents (excerpts) are sent to BERTopic fit to cluster documents and define topics.
BERTopic has a number functions to analyze and visualize topics. The “get_topic_Info” function provides the topic name, the number of documents and a sample document for the topic. Note that topic -1 is the set of documents that can not be clustered into a topic.
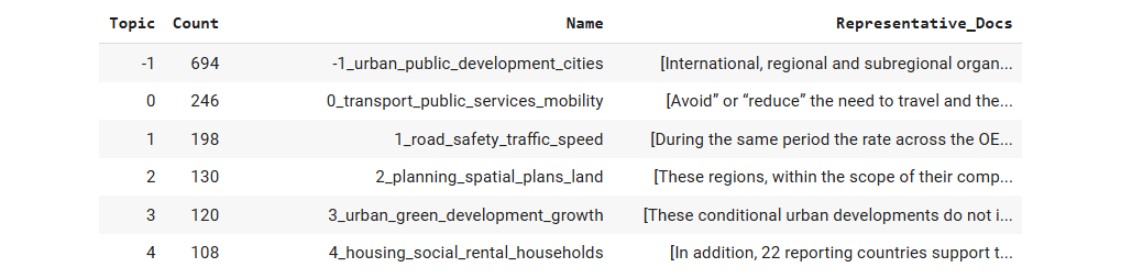 Sustainable Cities and Communities Topic Frequency
Sustainable Cities and Communities Topic Frequency
We can see important SDoH factors in the top 5 topics: transportation, road safety, spatial planning, green spaces and housing.
A bar chart visualization is provided showing the c-TF-IDF measure for each word in a topic. This counts how often each word appears in documents within a given topic and the importance of each word by calculating how unique or rare it is across all topics.
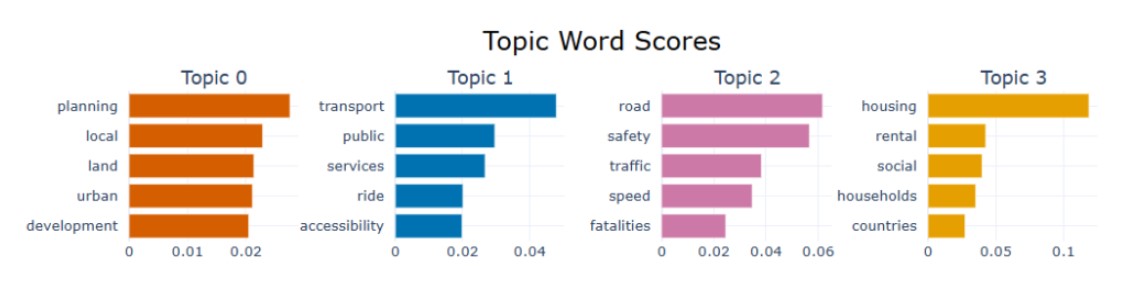 Sustainable Cities and Communities Topic Bar Chart
Sustainable Cities and Communities Topic Bar Chart
A document visualization shows a scatter plot of document embeddings in two dimensions. This helps you understand the distribution of documents across topics, showing how similar or distinct documents are from each other based on their embeddings.
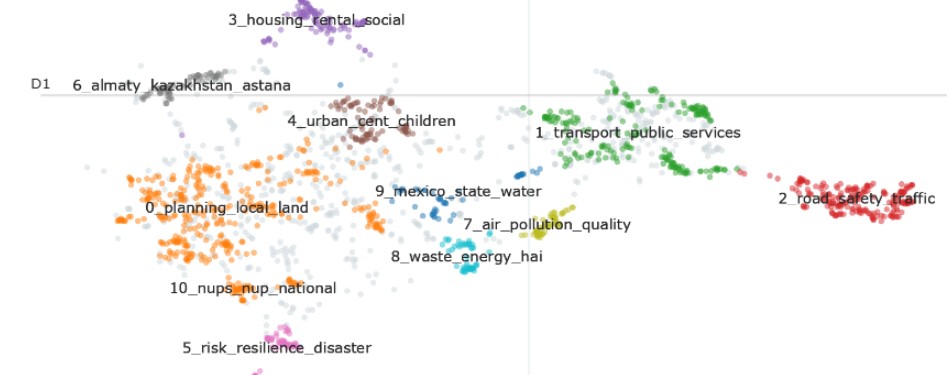 Sustainable Cities and Communities Topic Clustering
Sustainable Cities and Communities Topic Clustering
Conclusion
Topic modeling, particularly with tools like BERTopic, presents a promising approach for extracting insights into SDoH from unstructured text. Traditional data sources often lack the granularity or scope needed to capture the complexity of SDoH. Topic modeling, however, enables us to systematically analyze unstructured data to uncover critical themes and patterns. This method can empower healthcare, urban planning, and social service organizations by revealing social and environmental factors that impact health outcomes. Through the example of SDG 11, we demonstrated how topic models can surface themes such as transportation, green spaces, and housing, which are essential to creating equitable and sustainable communities. With continued advancements in NLP, topic modeling is becoming an invaluable tool for understanding and addressing the social drivers of health.
References
No responses yet